Brand Name Normalization Rules
By a data governance consultant with 10+ years building normalization pipelines for e-commerce, SaaS, and enterprise analytics platforms.
Table of Contents
TogglePicture this: your marketing dashboard shows three brands — “Nike,” “Nike Inc.,” and “NIKE.” Three separate line items. Three separate revenue figures. One company. That’s not a branding problem. That’s a data crisis hiding in plain sight.
Brand name normalization rules are the unglamorous fix that most organizations desperately need but rarely prioritize — until the quarterly report comes back with numbers that make no sense. As someone who’s audited brand data for companies ranging from two-person startups to multi-million-record e-commerce catalogs, I can tell you: messy brand data is almost always more expensive than fixing it. This guide covers the rules, the framework, and the real-world pitfalls nobody else talks about.
What Are Brand Name Normalization Rules?
Brand name normalization rules are structured guidelines that convert all variations of a brand’s name — different capitalizations, abbreviations, punctuation styles, legal suffixes, and regional spellings — into a single, standardized canonical form that can be used consistently across databases, analytics systems, CRM platforms, and SEO-facing content.
In plain terms: they decide that “Apple Inc.,” “apple,” “APPLE,” and “Apple®” are all the same thing, and that your system should store and display just one version. Research on data quality shows that up to 60% of data anomalies result from poor normalization practices, and normalized data improves consistency for more than 75% of organizations that implement it. That’s not a marginal gain — that’s the difference between analytics you can trust and dashboards you quietly second-guess.
Why Brand Name Consistency Rules Matter More Than Ever in 2026

The problem isn’t new, but it’s gotten dramatically worse.
Five years ago, most businesses had three or four data sources to reconcile: a CRM, a website, and maybe an ad platform. Today, that number is closer to fifteen or twenty — Shopify, Salesforce, Google Analytics 4, Meta Ads Manager, Amazon Seller Central, review aggregators, supplier feeds, third-party data warehouses. Each one accepts brand names as free-text fields. Each one has its own idea of how “McDonald’s” should be spelled.
But here’s the part that really changed things: AI and large language models now process your brand data. Google’s Knowledge Graph, product recommendation algorithms, and generative AI search overviews (in ChatGPT, Perplexity, and Google’s AI Mode) all rely on entity recognition — the ability to understand that all those variations refer to the same real-world brand. Search engines use structured data to understand brand relationships, and consistent brand naming improves entity recognition and trust signals. When your own systems can’t agree on how to spell your brand, you’re sending AI engines conflicting signals — and that costs you visibility.
And it’s not just search. Normalization can reduce storage costs by up to 30% and cut data redundancy by 50–90%. When you’re paying for cloud storage and compute on duplicate records, brand name inconsistency has a literal dollar cost attached to every row.
The 5-Layer Brand Name Normalization Framework
Most guides stop at “standardize your capitalization.” That’s Step 1 of 5. Here’s the complete picture.
Layer 1: Canonical Name Definition
Before you write a single rule, you need a canonical name — the one officially approved version of your brand name that all variations will map to. This sounds obvious, but I’ve seen companies with three internal departments each using a different “official” name. (Yes, this happens. Yes, it’s a nightmare.)
Your canonical name should reflect how customers search for and recognize the brand, not necessarily what appears on legal documents. “McDonald’s” is canonical. “McDonald’s Corporation” is not what people type into Google. This distinction matters enormously for SEO and e-commerce product matching.
Document the canonical name in a central registry — a master data management system, a shared spreadsheet with access controls, or a purpose-built tool like Ataccama or Informatica. The registry is the source of truth. Everything else maps to it.
Layer 2: Capitalization Rules
Decide whether your system uses title case, sentence case, or uppercase — and apply it universally. The most common standard is Title Case for consumer-facing content and the brand’s official stylization where it exists. “adidas” intentionally uses lowercase. “eBay” uses intercaps. Your rules need to account for these exceptions explicitly, not just apply a blanket transformation.
For brands without a strong official style preference, Title Case is the default most analytics systems and SEO-facing platforms expect. The mistake I see constantly: applying Title Case to everything, including brands like “adidas” or “iPad” — which then look wrong to anyone who knows the brand.
Layer 3: Punctuation, Special Characters, and Legal Suffixes
Legal terms such as “Ltd.,” “Inc.,” “LLC,” or “PLC” are usually excluded unless legally required. Symbols like ®, ™, and © are typically removed during normalization.
But — and this is where most guides get shallow — removing legal suffixes can create collisions. “Delta” the airline and “Delta” the faucet manufacturer are very different entities. If both appear in your catalog and you strip legal suffixes without context, you risk merging them. The fix is building collision detection into your normalization pipeline: flag any canonical name that matches an existing entry from a different industry or category before applying changes.
For special characters: accented letters (Café → Cafe), ampersands (H&M → H and M or H&M?), and hyphens (Coca-Cola vs. Coca Cola) each need explicit rules. There’s no universal right answer — but there needs to be a answer, documented and consistently applied.
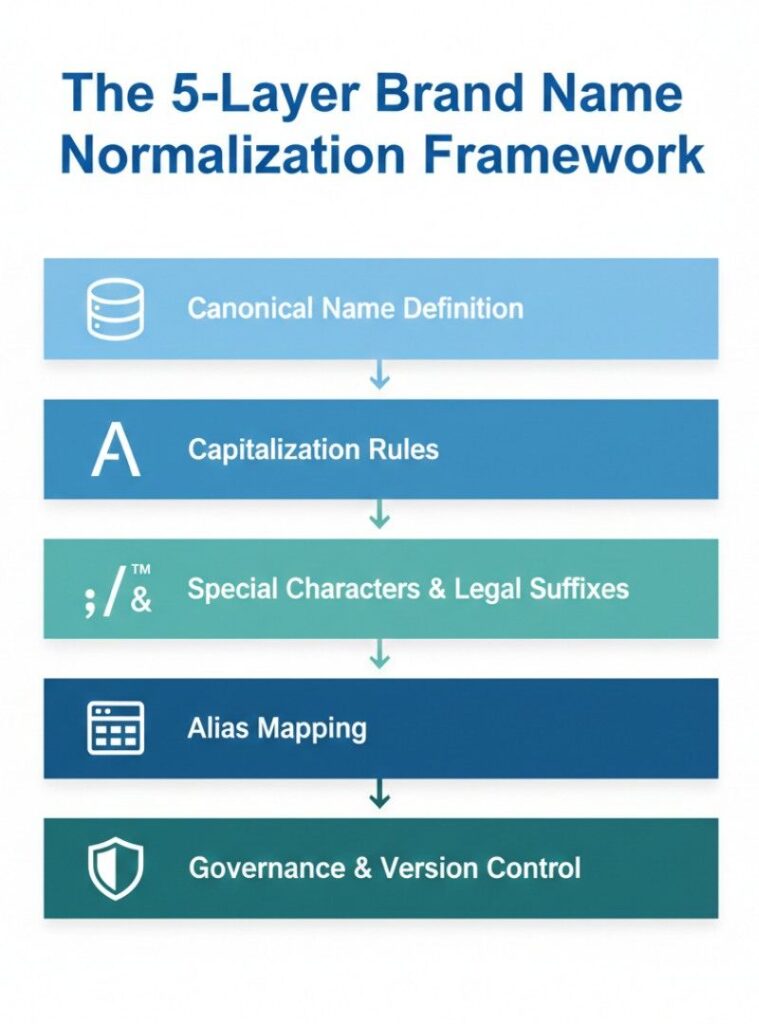
Layer 4: Abbreviation and Alias Mapping
Keep a reference table of known variants mapped to canonical names. For example, both “Samsung Electronics” and “Samsung Electronics L&T” should map to “Samsung.”
This alias table is genuinely the most labor-intensive part of normalization — and the most valuable. It’s where you capture the organic messiness of real-world data: user-generated content, OCR errors from scanned documents, regional abbreviations, outdated brand names post-acquisition.
I’ve built alias tables for mid-size e-commerce companies that ended up with 200+ variants for their top 50 brands. That sounds extreme until you realize that supplier data, customer reviews, and internal purchase orders each have their own vocabulary, accumulated over years, with no governance in place. The alias table turns that chaos into clean data automatically, on every new record that comes in.
Layer 5: Governance and Version Control
Here’s the layer competitors skip almost entirely.
Normalization isn’t a one-time project. Brands rebrand. Companies merge. New abbreviations emerge on social media and spread into your data. Without a governance layer — quarterly review cycles, a named owner for the canonical registry, audit logs tracking every change — your beautiful normalization system drifts back toward chaos within 18 months.
Assign a data steward. Set a review cadence. Use version control (even Git works for a canonical brand list stored as JSON or CSV). When Elon Musk renamed Twitter to X in 2023, any normalization system without a governance process suddenly had a new alias collision to handle — the hard way.

Rule-Based vs. ML-Based Normalization: Which Actually Works Better?
This comparison almost never appears in competitor articles, and the answer might surprise you.
Rule-based normalization — deterministic pipelines where you explicitly define every transformation — is predictable, auditable, and fast. You can explain every output. Regulators love it. Data teams trust it. But it doesn’t scale well when brand variations are genuinely unpredictable (user-generated content, international markets, OCR errors).
ML-based normalization — using fuzzy matching, entity resolution models, or LLMs to identify that “Procter & Gamble,” “P&G,” and “Procter and Gamble Co.” are the same — handles novel variations gracefully. It scales. But it introduces false positives (merging distinct brands that happen to look similar), and the outputs aren’t always explainable.
The honest answer, from practical experience: start with rules, extend with ML. Use deterministic transformations for known variants (your alias table handles 80–90% of cases). Use fuzzy matching or an LLM-assisted review process to flag and handle the remaining unknowns — but always with human review before those matches get committed to your canonical registry.
Normalization often happens first. Use rule-based transformations, alias mapping, and canonical storage fields. ML is a supplement, not a replacement.
Real-World Impact: What Normalized Brand Data Actually Changes
The business case for brand name normalization rules isn’t abstract. Here are concrete outcomes.
For e-commerce and retail teams: normalized brand names mean product filters actually work. When a customer filters by “Sony,” they see every Sony product — not just the ones where the supplier happened to spell it correctly. Third-party sellers often introduce inconsistent brand naming. Normalization rules automatically clean incoming data before it goes live.
For analytics and BI teams: revenue attribution becomes reliable. If “Procter & Gamble” and “P&G” are treated as separate entities in your sales data, your brand-level performance reports are wrong — not slightly wrong, materially wrong. I’ve seen this cause incorrect inventory forecasting that cost a mid-size distributor six figures in overstock.
For SEO and content teams: entity consistency across your website, structured data markup, and internal linking directly influences how Google’s Knowledge Graph associates your content with brand entities. Brand name normalization rules improve SEO by ensuring consistent brand references across platforms, improving search engine indexing and visibility.
For paid media teams: keyword targeting quality improves when brand mentions are normalized across ad copy, landing pages, and product feeds — particularly for exact-match and phrase-match campaigns where a single character difference can exclude a variation.
However — and this is worth being direct about — normalization can introduce problems if applied carelessly. Over-normalization merges distinct entities. “Delta” the airline and “Delta” the faucet brand should never be merged. “Facebook” and “Meta” require careful handling during and after rebranding transitions. Build collision detection. Test edge cases. Don’t treat normalization as a fully automated fire-and-forget process.
FAQs: Brand Name Normalization Rules
Normalization standardizes the format of brand names — fixing capitalization, abbreviations, punctuation. Deduplication removes redundant records that refer to the same entity. Normalization typically runs first; clean, standardized names make deduplication far more accurate and reliable.
Use the brand's official stylization when it's known and widely recognized — "adidas," "eBay," "iPhone." For lesser-known brands without strong style requirements, apply Title Case as your default standard. The goal is matching how customers recognize and search for the brand.
Quarterly reviews are common for most organizations. Update immediately when a major brand rebrands (Twitter → X), when you onboard a new data source with different naming conventions, or when data quality reports flag a spike in unmatched variants.
Yes, indirectly but meaningfully. Consistent brand name usage across your site, structured data (Schema.org), and external platforms strengthens entity recognition signals. Google's Knowledge Graph uses these signals to associate your content with brand entities, which influences branded search rankings and appearance in AI-generated overviews.
For smaller datasets: start with OpenRefine (free, open source) or even well-structured spreadsheet VLOOKUP tables. For mid-scale operations: data quality tools like Talend or dbt transformations in a data warehouse. For enterprise: master data management platforms like Informatica MDM, Ataccama, or Reltio.
Not yet, for most production use cases. Fuzzy matching handles novel variations well but introduces false positives — merging distinct brands that look similar. Always include a human review step before committing ML-suggested matches to your canonical registry.
This is the most common serious mistake. Over-normalization creates worse problems than it solves — incorrect attribution, inventory errors, and SEO signals that associate different brands together. Build explicit collision detection and test every rule against a sample dataset that includes known-distinct brands with similar names.
Yes, and this gets complex quickly. "Nike Air Max" is a product line, not a separate brand — but depending on your system, it may need its own canonical entry. Define a clear hierarchy: parent brand → sub-brand → product line, and ensure your normalization rules respect that hierarchy rather than flattening everything into one level.
After a decade of cleaning brand data for companies of every size, here’s what actually matters:
Start with your canonical list, not your rules. Normalization rules without a defined canonical name to map to are just transformations with no destination. Build the registry first.
The alias table is where the real value lives. A rule that says “convert to Title Case” is easy. A table that says “Samsung Electronics Co., Ltd.” → “Samsung” is the product of real knowledge about your data — and it’s irreplaceable.
Governance is the part that makes it last. Every normalization project I’ve seen succeed had a named owner and a review cadence. Every one I’ve seen fail had neither.
Whether you’re managing a small product catalog or a multi-million-record enterprise data warehouse, brand name normalization rules aren’t optional — they’re the foundation everything else is built on.
Ready to start? Audit your top 50 brands today. Count how many variants exist for each. That number will tell you everything you need to know about the scale of the problem — and the opportunity.
